
The Mystery
We’ve all been there. We enter a prompt into an AI Agent, and then we wonder why it chose to invoke a particular Tool in a particular MCP server. Or the flip side – why it didn’t invoke a Tool that you expected it to invoke.
As it turns out, the explanation of how MCP Tools are chosen is both simpler and more nuanced than most people think.
Below, I describe how an AI Agent/LLM decides whether to call an MCP Tool, which tool to call, and when not to call one.
How an LLM Decides to Call MCP Tools
MCP (Model Context Protocol) is designed so that external Tools can become part of the LLM’s (Large Language Model) decision-making environment. But note that the LLM doesn’t run tools on its own — it selects Tools based on the conversation context, various Tool schemas, and the LLM’s own internal decision heuristics.
The following mental model explains how it works.
The LLM sees each Tool as a function with a “contract”
The term “MCP Tool contract” refers to the MCP specification that defines how AI Agents communicate with external Tools and services. This protocol standardizes the interaction, acting as a universal interface between LLMs and the functions they can call to perform actions or access data.
This contract is the schema and metadata that describe a Tool’s capabilities, inputs, and expected outputs.
Every MCP Tool provides a definition structure that contains:
- A name
- A description
- A JSON schema describing its expected input parameters and output shape
- (Optionally) a declared set of “hints” related to tool behavior
In this article, I will defer discussing detailed aspects involving vector representations (embeddings), named entity recognition (NER), etc. But at a high level, it is essential to understand that the Agent ingests the Tool’s definition structure, and then the LLM forms a semantic signature that represents the Tool.
When Agents connect to an MCP server, the Tools metadata — an array with names, parameter schemas, descriptions, etc. — becomes vectorized inside the LLM. This produces an internal “tool embedding” for each Tool.
Later, during NLP operations (input prompts from the user to the Agent), the LLM uses this semantic signature embedding to infer:
- What each Tool does
- What kinds of problems the Tool solves
- What inputs the Tool needs
- What situations require calling the Tool
This is why high-quality Tool names, descriptions, and parameter descriptions matter so much when building MCP Tools.
Tool descriptions are not procedural instructions. They become semantic memories that the LLM embeds and can later compare against natural language.
Without embeddings, the LLM…
- would not generalize to synonyms (“remove identity” → “delete identity”).
- would not understand parameter semantics.
- could not decide when not to use a tool.
- wouldn’t handle partially matching prompts.
Embeddings make Tool utilization a meaning- or intent-matching task, not a keyword-matching task.
LLMs store tool descriptions as dense semantic vectors, then compare the vectorized user prompt against these internal “tool embeddings” to decide if a tool should be invoked, which one, and how to populate its parameters.
The LLM maps user intent → candidate tool(s)
Based on the user’s latest message, the LLM internally performs an intent classification step (not externally visible to the user). Essentially, the LLM asks itself:
- “Does the user want information that I can answer myself?”
- “Is the user requesting an operation that requires a tool?”
- “Is the user asking for data I don’t know?”
- “Is the user asking for something explicitly mapped to a tool (e.g., search, sql.query, filesystem.readFile)?”
Tools are only chosen if:
- The intent requires external action
- A tool exists whose schema/description has a semantic match
- The Tool’s input parameter constraints match the user’s request
The LLM tends to be conservative: if it can answer without a tool, it will.
The LLM evaluates all tools against the current query
Again, internally, it reasons out something like: “Given the user’s intent, which available tools appear relevant?”
For each tool, it checks:
- does the description mention relevant verbs/nouns?
- does the schema accept the type of arguments the user is asking about?
- is it plausible that this tool can fulfill the request?
- do other tools overlap with this one?
This amounts to semantic similarity search + heuristics, not code execution.
The LLM predicts the tool call as text, not by executing logic
This is an important subtlety.
The LLM doesn’t run the tool or simulate its output before choosing it. It predicts the next token, which happens to be a JSON object that the Agent framework interprets as a tool call.
If the next-token probability distribution supports a tool invocation pattern, you will see a tool call.
So the LLM isn’t “deciding” in the human sense — it’s predicting tool-call tokens when they appear appropriate, given the prompt, chat history, tool descriptions, and system guidelines.
The hosting Agent may also influence the decision
Depending on the agent framework (Anthropic’s, OpenAI’s, LangChain, or even your own custom MCP runner):
- The “system prompt” may strongly encourage tool usage
- Some frameworks inject “use a tool if… rules”
- Some frameworks forbid the model from answering directly in certain domains
- Some attach safety rails (e.g., “never call X tool without explicit user confirmation”)
These meta-rules significantly affect tool selection.
Note that the MCP server NEVER sends a system prompt. The MCP server only provides:
- tools → list of tool descriptions
- resources
- prompts
- executable operations when the model calls them
But the MCP server never includes actual pre-instructions for the LLM.
This is intentional.
The system prompt must come from the client who is orchestrating the conversation. Let’s use the Claude Desktop Agent as an example of an MCP client.
When you add an MCP server to Claude Desktop, the sequence looks like:
- Claude loads your MCP manifest
- Claude indexes your MCP tools
- Claude writes the system prompt internally (you never see it)
- Claude injects imported tool descriptions into the context
- Claude responds to user messages
You cannot change the system prompt in Claude Desktop today. The client controls it, not the tool server.
If you build your own agent using, say, the official Node SDK (@modelcontextprotocol/sdk), you can certainly provide your own system prompt.
Example:

Here, you, as the developer, decide the system prompt.
How the System Prompt and Tool Descriptions Merge

This is exactly what Agents like ChatGPT and Claude Desktop do behind the scenes.
When the model decides not to call a tool
The model avoids tools in these cases:
- The user asks a conceptual question that the model can answer. For example: “What’s the difference between OAuth and OpenID Connect?”
- The tool’s description is unclear or mismatched. For example, if your tool says “GetItem” but the description doesn’t explain what item, the model will most likely ignore the Tool.
- The tool appears risky or destructive. (“delete”, “modify”, etc. — unless explicitly instructed)
- The model isn’t confident that it can satisfy the schema. For example, if the user gives incomplete parameters and the model can’t infer them, it probably won’t call the tool.
Models also learn from prior tool calls in the conversation
The more carefully you write:
- tool names
- descriptions
- examples
- schema
…the more likely the model will correctly choose them.
Good Tools feel like natural language functions.
Bad Tools feel like weird API endpoints the model tries to avoid.
Designing Tools the LLM Will Actually Use
Use a strong, unambiguous, action-oriented tool name
Bad:
- process
- nf-tool
- ziti-op
Good:
- listIdentities
- createTunnel
- generateJWT
Description should be one short paragraph telling the model exactly when to use it
Bad:
“This tool queries the backend.”
Good:
“Use this tool whenever the user wants to look up the details of a specific identity in Ziti by ID or name.”
Include natural-language cues that the model will remember
Examples:
- “Use only when…“
- “Call this tool if the user asks for…”
- “This tool is used to search, fetch, modify, calculate, etc.”
Tool descriptions should not be vague
Don’t use:
“Does something with deployments.”
Do use:
“Returns full deployment metadata including version, manifest, dependencies, and status, for auditing or debugging.”
Parameter names should be obvious and self-explanatory
Bad:
{ “id”: “string” }
Good:
{ “identity_id”: “The Ziti identity ID (uuid) to look up.” }
Avoid deeply nested schemas
LLMs can struggle with:
- huge nested objects
- recursive schemas
- 8+ required parameters
If possible:
- flatten fields
- group complex objects into “options” or “config” fields
Use examples when possible
Example fields are very influential.
Examples of GREAT vs. BAD tool descriptions
Great
“createUser”: {
“description”: “Create a new user record. Use this when the user asks to register, sign up, or create an account. Requires a unique email.”,
“parameters”: { … }
}
Why it works:
- clear trigger conditions
- specific verbs
- clear unique requirement
- simple schema
Bad
“createUser”: {
“description”: “User tool for accounts.”,
“parameters”: { … }
}
Why it fails:
- The description does not match any user intent
- no triggers
- unclear purpose
DEMO
I learned most of what is discussed above while building some MCP Server prototypes related to some AI functionality that NetFoundry will be rolling out soon.
To illustrate what can go wrong if you haphazardly design your Tools, I will show you some real examples, using the Claude Desktop Agent as the client.
I will demonstrate some internal Tool definitions used in an early prototype of an OpenZiti MCP Server, capable of being embedded within the Claude Desktop AI Agent.
NOTE: This OpenZiti MCP Server is intended to enable the use of natural language for managing a Ziti network. Yes, you heard that correctly… soon, you will be able to type ordinary human language queries or commands into Claude, and those operations will execute against your selected OpenZiti network. More on this below…
Here is an admittedly contrived, very badly written (and perhaps tortured) Tool definition:
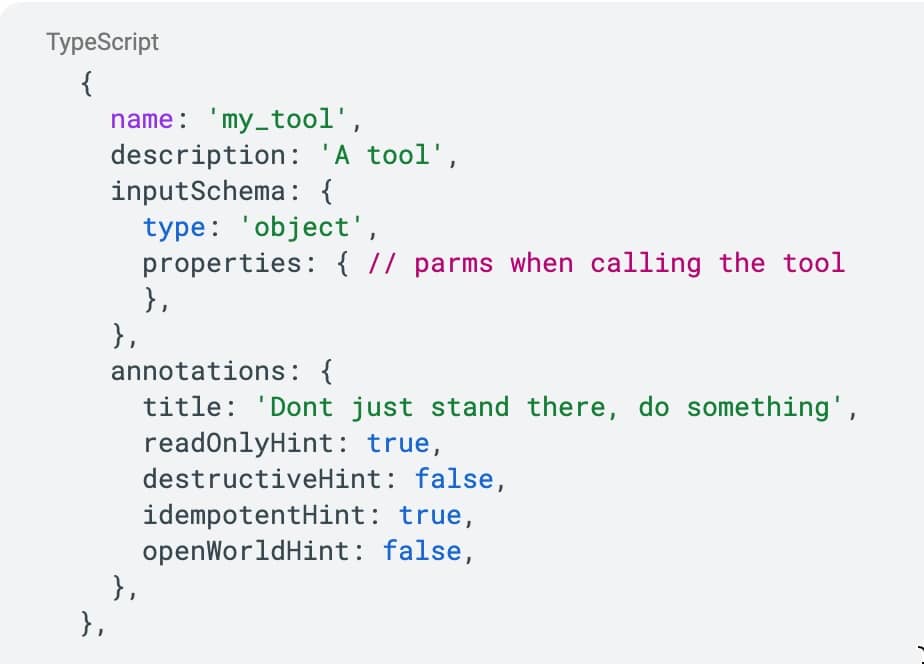
This Tool has no mention of Ziti or any Ziti constructs (such as Identities).
Let’s find out what happens in Claude if I attempt to accomplish something related to a Ziti network, such as getting a list of existing Identities.
By the way, it is worth noting that the my_tool Tool in this silly example is actually wired up with a function that can securely access the Ziti Controller’s management API and fetch Identities (the details of which are a topic I will discuss in an upcoming article). So, if the Claude Desktop Agent somehow made the association between a user prompt and this my_tool Tool, then Identity information would indeed be fetched from the Ziti Controller’s management API and returned to Claude.
OK, once my MCP Server and its Tools are installed in Claude Desktop, I can enter the prompt:
“can you help me determine what identities exist in the network?”
Claude ponders for quite a while, then gives up and says this:
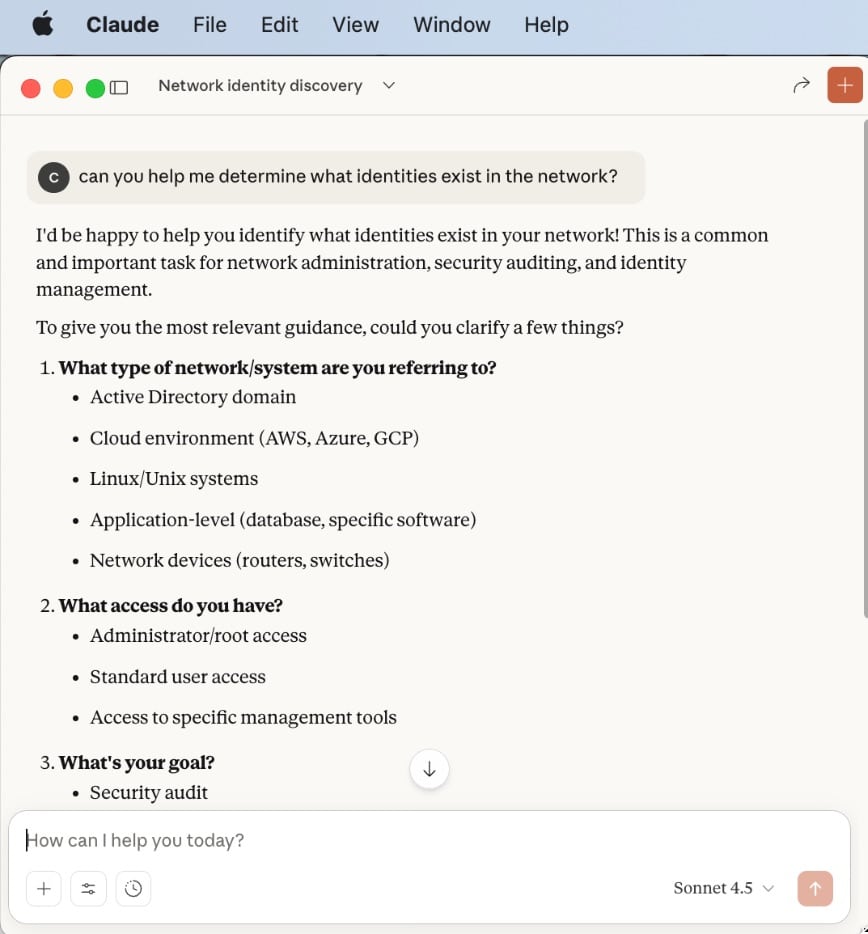
It is abundantly clear that the Claude Desktop Agent (the MCP client) did not have the necessary data (i.e., the proper vector embeddings) to associate the semantics contained in the prompt with a Tool capable of carrying out the task.
Claude had no notion of Ziti networks at all, let alone how to obtain a list of Identities that exist in the network. This is not a surprise, given how poorly the contrived Tool definition was written.
Now, let’s craft a good Tool definition.
We’ll replace the contrived example shown above with a proper one that adheres to best practices concerning Tool definition. We’ll give it a very detailed description, and a name that makes it obvious to the LLM what the Tool is intended for:

Now watch what happens in Claude after I reinstall my MCP server with this Tool definition, and I then attempt to accomplish the same task of listing existing Identities.
When I re-enter the same prompt:
“can you help me determine what identities exist in the network?”
Claude now says this:
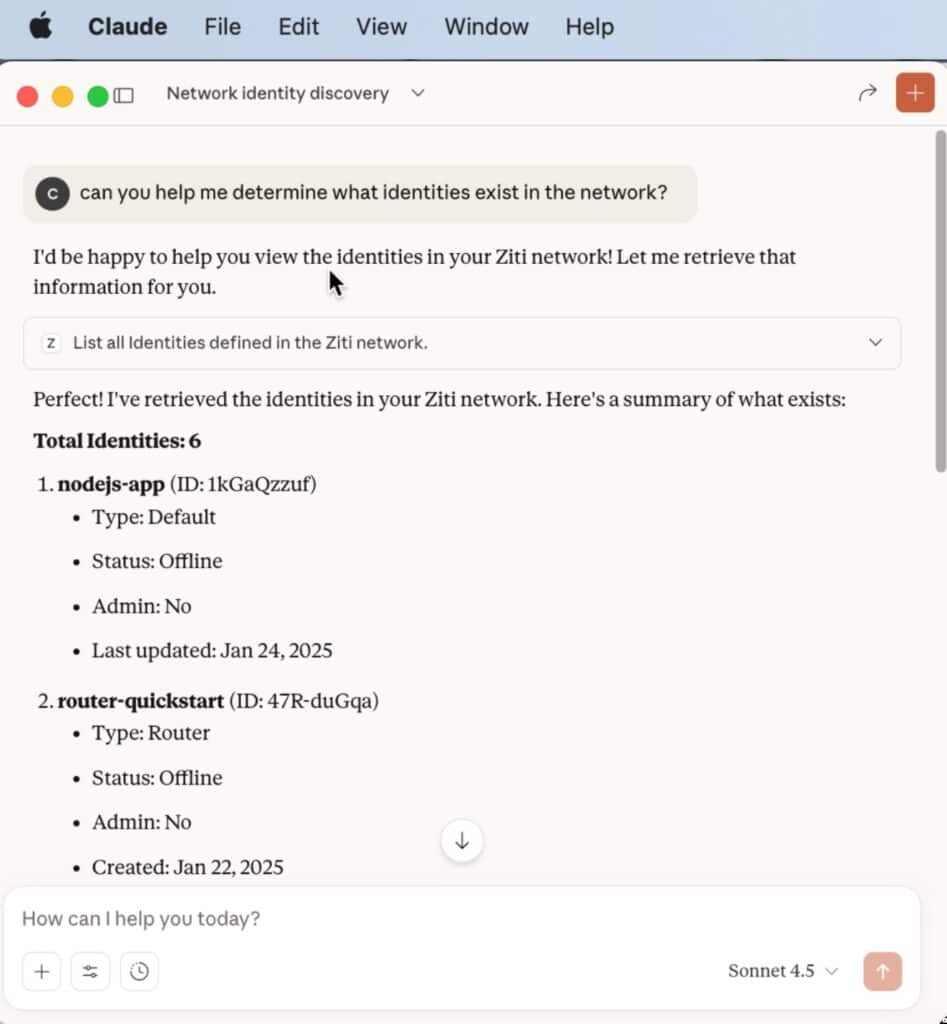
Success!
As you can see, since the Agent was provided a proper Tool definition, the LLM was allowed to generate proper embeddings for the Tool, then use the embeddings to understand the semantic meaning of the prompt, then associate that meaning with the appropriate Tool, and finally send a request to the Tool best suited to carry out the task.
Conclusion
The OpenZiti MCP Server highlighted in the DEMO section above is capable of being embedded within Claude Desktop, so you can also use natural language to manage your Ziti network.
What’s also exciting is that this OpenZiti MCP Server is also capable of being embedded into the many AI Coding Agents available today (e.g., Cursor, Windsurf, VSCode). This will allow developers to integrate OpenZiti SDKs into their applications much more quickly and easily (watch for upcoming articles on that).
As an engineer at NetFoundry, I am involved in crafting OpenZiti and related technologies, such as the OpenZiti MCP Server you saw glimpses of above.
If using natural language to manage your Ziti network sounds interesting to you, please use this form to express your interest. We are wrapping up the initial version of this MCP server, and you can be among the first to try out the beta…so be sure to get on the list.
Beyond this discussion of local, Agent-embedded MCP servers, if you run your own MCP servers that are accessed remotely over the internet, and you are curious about how to protect them with secure access, in a simplified manner, we can help. So reach out and talk to us.














